Was ist ein Canonical?
Das Canonical-Tag ist ein Attribut innerhalb eines Link-Elements im Header des Quelltextes einer URL, das dabei hilft die Indexierung einzelner Unterseiten durch Suchmaschinen zu steuern. Es wird auf URL-Basis ausgezeichnet und eingesetzt, wenn auf Webseiten identische oder sehr ähnliche Inhalte über mehrere Unterseiten aufrufbar sind. Das Tag sagt dem Crawler von Suchmaschinen, welches Dokument die Originalquelle eines Inhalts ist und entsprechend indexiert werden soll. Die Auszeichnung per Canonical-Tag wird von Google aber eher als Empfehlung bewertet. Dementsprechend behält sich die Suchmaschine vor, selbst zu entscheiden, welche URL indexiert wird. Sprechen andere Signale dafür, dass eine andere URL relevanter ist (zum Beispiel viele interne Links oder abweichender Content), ist die Wahrscheinlichkeit hoch, dass diese stattdessen indexiert wird. Die URL, die als Original-Quelle angegeben wird, bezeichnet man als kanonische URL. Die anderen URLs, die per Canonical Tag auf die Originalquelle verweisen, sind die kanonisierten URLs. Das Canonical ist ein mächtiges Werkzeug, mit dem ihr Probleme mit Duplicate Content auf eurer Website lösen könnt. Wird es fehlerhaft verwendet, kann es aber auch dafür sorgen, dass komplette Website-Bereiche deindexiert werden und nicht mehr über Suchmaschinen auffindbar sind. Ein Canonical-Tag sollte daher nur dann eingesetzt werden, wenn es keine alternative Lösung für das Duplicate Content Problem gibt. Idealerweise entsteht erst gar kein Duplicate Content auf eurer Website.Warum ist Duplicate Content schädlich?
Aus SEO-Sicht sollten Inhalte auf Websites immer nur einmal vorhanden, also nur über eine URL erreichbar sein. Dies ist vor allem für die Indexierung einzelner Unterseiten wichtig. Wenn es mehrere Unterseiten mit identischen oder ähnlichen Inhalten gibt, wird von Duplicate Content oder Near Duplicate Content gesprochen und das wird von Google abgestraft. Google möchte für jede Suchanfrage nur ein Ergebnis ausliefern, nämlich das, das am besten passt. Besteht Duplicate Content, ist es für die Suchmaschine schwierig, richtig zu beurteilen, welche der URLs diejenige ist, die indexiert werden soll und somit den passenderen Inhalt für eine Suchanfrage darstellt. Dadurch kann eine sogenannte Keyword-Kannibalisierung entstehen: Google stuft die URLs mit den identischen oder sehr ähnlichen Inhalten als relevant für dasselbe Keyword ein. Beide Unterseiten ranken gleichzeitig für dasselbe Keyword oder wechseln sich ab. Mal rankt die eine, mal die andere. Auf lange Sicht leidet darunter das Ranking. Im schlimmsten Fall wird die relevantere bzw. die für euch wichtigere Seite abgewertet oder keine der beiden URLs rankt mehr. Für Google ist die Duplicate Content Thematik noch aus zwei anderen Gründen wichtig. Auf der einen Seite ist Google darum bemüht nur relevante URLs in den Index der Suchmaschine aufzunehmen. Doppelte Inhalte sind nicht relevant. Auf der anderen Seite verbraucht das Crawlen von Unterseiten Ressourcen. Je mehr Ressourcen für das Crawlen eurer Website von Google benötigt werden, desto teurer wird der Crawling-Prozess für Google. Daher ist die Suchmaschine bemüht nur relevante URLs zu crawlen. Sind sehr viele Inhalte doppelt vorhanden, wird Crawl-Budget an URLs ohne Relevanz verschwendet. Dies kann sich unter Umständen negativ auf die SEO-Performance der gesamten Website auswirken. Kanonisierte URLs werden nicht so häufig und zum Teil sogar gar nicht mehr gecrawlt. Hier könnt ihr nachlesen, was passiert, wenn es auf einer Website viel technischen Duplicate Content gibt, aber eine einheitliche Strategie zum Umgang damit fehlt.Wie wird der Canonical-Tag richtig gesetzt?
Das Canonical-Tag wird im Header des HTML-Codes bzw. Quellcodes gesetzt und verweist auf die entsprechende Standardressource. <head> <link rel="canonical" href=http://www.luna-park.com/blog/canonical-tag/ /> </head>
Beispiel von der lunapark Website
Wann kann ein Canonical-Tag verwendet werden?
Es gibt ein paar typische Anwendungsfälle, bei denen es ratsam ist Canonical-Tags zu verwenden. Sinnvoll ist die Anwendung allerdings nur dann, wenn es keine andere Möglichkeit gibt, den Duplicate Content zu beseitigen (z.B. durch Weiterleitungen, Linkmaskierung oder die Eliminierung doppelter Inhalte).- Die Startseite ist über mehrere URLs erreichbar. https://www.luna-park.de/ , https://luna-park.de, https://luna-park.de/index.html
- Seiten, die sowohl mit Trailing Slashes (/) als auch ohne geöffnet werden können. https://www.luna-park.de/blog/28989-google-snippets-schreiben/, https://www.luna-park.de/blog/28989-google-snippets-schreiben
- Bei der Nutzung von dynamischen URLs oder auch bei URLs mit Parametern, die den Seiteninhalt kaum bzw. gar nicht verändern. Beispiele wären hier u.a. Filterparameter oder Session-IDs. Bei der Verwendung solcher URLs muss das Canonical-Tag auf die Originalseite zeigen (in der Regel die Seite ohne Parameter) und der Canonical-Tag auf der Originalseite zeigt auf sich selbst.
- Wenn Inhalte in verschiedenen Formaten abrufbar sind, wie zum Beispiel Seiteninhalte, die zusätzlich als PDF vorliegen oder wenn es eine Druckansicht der Inhalte gibt.
- Bei Inhalten, die ebenfalls auf anderen Websites veröffentlicht wurden, wie zum Beispiel bei Gastbeiträgen in einem Blog.
- Wenn Seiten unter verschiedenen Protokollen erreichbar sind, also http und https.
Welche URL stuft Google als kanonisch ein?
Da Google das Canonical-Tag eher als Empfehlung einstuft, kann es vorkommen, dass dieser Empfehlung nicht gefolgt wird. Mit Hilfe der Search Console könnt ihr einsehen, welche URL von Google als kanonische URL angesehen wird. Verwendet dazu die URL-Prüfung und gebt die entsprechende URL ein. Unter „Indexierung“ zeigt euch das Tool an, ob eure als kanonisch angegebene URL mit der von Google ausgewählten URL übereinstimmt.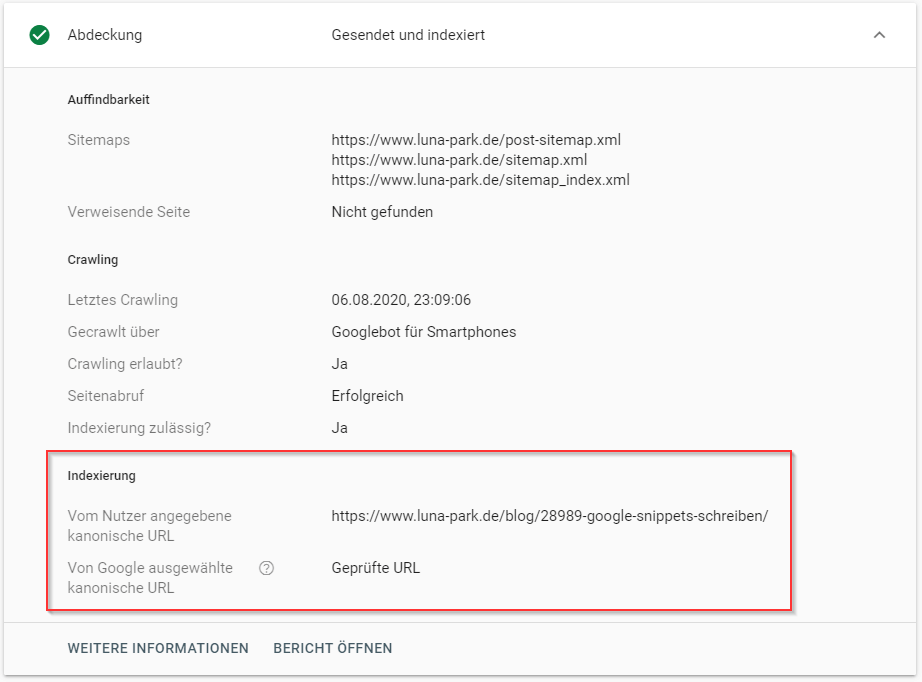
Prüfen, welche URL Google als kanonische einstuft
Häufige Fehler bei der Verwendung eines Canonical-Tags
Der Canonical-Tag ist eine gute Möglichkeit einer Abstrafung wegen Duplicate Content zu umgehen. Allerdings wird er häufig falsch verwendet oder an falscher Stelle genutzt. Das kann fatale Folgen für die Indexierung der Website haben. Im Folgenden wird auf die häufigsten Fehler bei der Verwendung von Canonical-Tags eingegangen, die ihr auf jeden Fall vermeiden solltet.Canonical-Tag im Body
Ein weit verbreiteter Fehler ist, dass das Canonical-Tag in den Body des Quellcodes anstatt in den Header gesetzt wird. Dies hat zur Folge, dass er von Google ignoriert wird und somit keine Auswirkungen hat. Somit wäre der Canonical-Tag sinnlos und es bleibt bei dem Duplicate Content Problem und der Verschwendung von Crawl-Budget.Mehrere Canonical-Tags auf einer Unterseite
Es kann vorkommen, dass mehrere Canonicals auf einer Unterseite vorhanden sind. Dies ist zum Beispiel dann der Fall, wenn ein Template kopiert wird, das bereits einen Canonical-Tag hat. Auch passiert dies häufig bei Content-Management-Systemen wie WordPress, bei denen die Canonicals über ein Plugin gesetzt werden. Wenn hier sowohl das Plugin verwendet wird, gleichzeitig aber auch manuell im Quellcode Angaben gesetzt werden, doppeln sich diese und widersprechen sich sogar. In diesem Fall ignoriert Google den Canonical-Tag.Canonical-Tags bei relativen URLs
Grundsätzlich ist die Verwendung von relativen URLs bei Canonical-Tags möglich. Allerdings kann dies zu einigen Problemen führen. Dies ist der Fall, wenn die Inhalte einer Domain sowohl unter http als auch unter https oder unter verschiedenen Domains mit denselben Pfaden aufrufbar sind.Kanonisierte URLs in robots.txt gesperrt
Über die robots.txt können bestimmte URLs blockiert werden, so dass verhindert wird, dass diese von Suchmaschinen gecrawlt werden. Wenn kanonisierte URLs durch die robots.txt blockiert werden, dann kann Google die Canonical Tags auf den Seiten nicht sehen und somit verarbeiten. Auch wird dadurch verhindert, dass die Link-Power von der nicht-kanonischen URL auf die kanonische URL übertragen wird.Canonical-Tag und „noindex“-Tag
Verwendet man Canonical-Tags und „noindex“-Tag auf dergleichen Unterseite, so werden Google zwei entgegengesetzte Anweisungen gegeben. Das Canonical-Tag teilt Google mit, dass es zwei identische oder sehr ähnliche Seiten gibt. Der Meta-Robots-Tag „noindex“ gibt dagegen die Anweisung, dass die Seite nicht indexiert werden soll. Es soll sogar vorkommen, dass der noindex-Tag auf die kanonische URL übertragen wird und so beide URLs aus dem Index fliegen. Grundsätzlich sollten Canonical-Tags daher nicht zusammen mit „noindex“ verwendet werden.Canonical-Tags und 404-Statuscode
Verweist ein Canonical-Tag auf eine Seite, die den Statuscode 404 hat, wirkt sich das negativ auf die Sichtbarkeit in den Suchergebnissen aus. Bei der Verwendung sollte daher immer darauf geachtet werden, dass der Inhalt, auf den das Canonical-Tag verweist, auch wirklich existiert.Canonicals bei unterschiedlichen Inhalten
Wenn Unterseiten mit sehr unterschiedlichen Inhalten auf eine gemeinsame kanonische URL verweisen, kann dies zur Folge haben, dass alle Unterseiten, ausgenommen der kanonischen URL, aus dem Index fallen. Sie tauchen nicht mehr in den Suchergebnissen auf und erhalten entsprechend keinen organischen Traffic mehr. Fatal ist es zum Beispiel, wenn alle Unterseiten per Canonical auf die Startseite verweisen.Canonical-Tag bei paginierten Seiten
Von Paginierung wird gesprochen, wenn Inhalte auf mehreren Seiten verteilt werden und diese dann „durchgeblättert“ werden können. In den meisten Fällen tauchen diese in Shops für die Produktübersicht auf oder auch in Archiven von Blogs oder Online-Magazinen.
Beispiel für paginierte Seiten
Fehlender Canonical-Tag bei URL-Parametern
In der Regel werden Websites zunächst ohne Canonical-Tag online gestellt. Dabei wird häufig vergessen, dass durch Tracking, Filterungen oder Ähnliches URL-Parameter entstehen können und diese führen dann zu ungewolltem Duplicate Content. Aus diesem Grund ist es ratsam ein Canonical-Tag zu setzen.Canonical-Tag und hreflang Link-Attribut
Problematisch ist auch die gleichzeitige Verwendung von Canonicals und hreflang-Auszeichnungen, da diese widersprüchliche Signale senden können. Bei der gemeinsamen Verwendung von Canonical-Tags und hreflang-Attributen sollten die Inhalte wirklich zu 100% identisch sein. Da dies in der Regel nicht der Fall ist, sollte auf eine gemeinsame Verwendung verzichtet werden.Canonical-Ketten
Wie auch bei Weiterleitungen sollten lange Canonical-Ketten vermieden werden. Canonical-Ketten können vorkommen, wenn zum Beispiel Inhalte auf verschiedenen Websites vorhanden sind, die jeweils aufeinander verweisen.Fehlender Canonical-Tag bei mobiler URL
Ist eine Website nicht responsive und somit auf Desktop und Mobile nicht über dieselbe URL erreichbar, gibt es in der Regel eine separate Mobilversion. Dabei sollte ein Canonical-Tag auf der Mobilversion gesetzt werden, der die Desktopversion als Hauptressource angibt. Fehlt dieser Verweis, führt dies dazu, dass die komplette Website als Duplicate Content angesehen wird. Dies wirkt sich entsprechend negativ auf die Sichtbarkeit aus.Canonicals prüfen mit dem Screaming Frog?
Es gibt viele – zum größten Teil kostenpflichtige – Tools, mit denen Canonicals geprüft werden können. Dazu gehört zum Beispiel der Screaming Frog. Das Tool ist für 500 URLs kostenlos, danach kostet es ca. 150,00 Dollar im Jahr. Der Screaming Frog crawlt die im Header des html implementierten Canonicals, so dass ihr auf einem Blick sehen könnt, welche URLs kanonisiert sind und welche kein Canonical-Tag haben. Außerdem zeigt er euch, welche Unterseite als kanonische URL angegeben ist.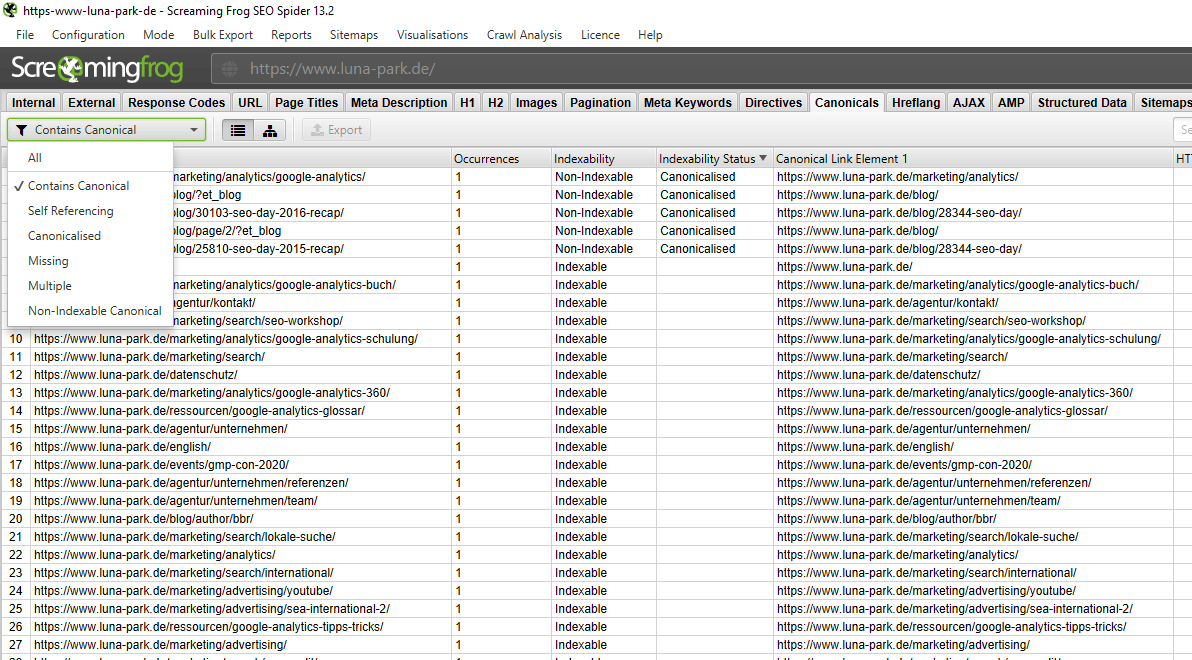
Canonical Bericht im Screaming Frog
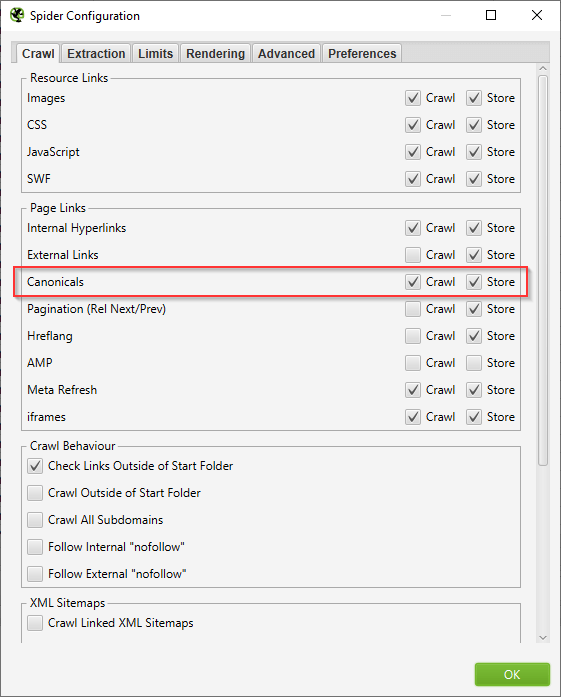
Konfiguration im Screaming Frog


