Bei sehr großen Websites tritt häufig das Problem auf, dass der Googlebot sie nicht vollständig crawlt, relevante Unterseiten aus diesem Grund nicht indexiert werden und dann auch nicht ranken. Mit der robots.txt können die Crawler der Suchmaschinen gesteuert werden. Was die robots.txt genau ist, wo sie verankert sein muss, wie sie funktioniert und welche Vorteile für SEO damit generiert werden, erfahrt ihr im folgenden Beitrag.
Inhaltsverzeichnis
- 1 Was ist die robots.txt?
- 2 Wo befindet sich die robots.txt?
- 3 Wie funktioniert die robots.txt?
- 4 Braucht man zwingend eine robots.txt?
- 5 Welche Vorteile bietet die robots.txt für Domainbetreiber?
- 6 Wie ist eine korrekte Robots.txt aufgebaut?
- 7 Wie reiche ich eine neue robots.txt bei Google ein?
- 8 Worauf muss man bei der robots.txt achten?
- 9 Fazit
Was ist die robots.txt?
Die robots.txt („Robots Exclusion Standard Protokoll“, kurz REP) ist eine Textdatei, in der festgelegt wird, welche Dateien oder Seiten von sogenannten Crawlern angefordert werden können und welche nicht. Sie beinhaltet also Regeln für Webcrawler, die besagen, wie sie sich durch eure Website bewegen dürfen. Das ist vor allem für Webseiten-Betreiber großer Domains interessant.

Beispiel robots.txt
Wichtig zu wissen ist, dass die robots.txt-Datei kein Mechanismus ist, der euch hilft, einzelne Seiten von der Google-Suche zu entfernen. Sie ist also nicht zum Steuern der Indexierung gedacht. In erster Linie dient die Datei dazu, zu vermeiden, dass eure Website durch eine Vielzahl von Anfragen überlastet wird.
Wo befindet sich die robots.txt?
Die robots.txt wird im Root-Verzeichnis eurer Domain hinterlegt. Hierbei ist entscheidend, dass die Textdatei unter der entsprechenden URL aufzurufen ist (Beispiel: https://www.eure-domain.de/robots.txt). Solltet ihr sie also anderorts verankert haben, oder nicht als Text- sondern HTML-Datei angelegt haben, wird sie mit großer Wahrscheinlichkeit nicht funktionieren.
Wie funktioniert die robots.txt?
Das Dokument wird von Bots bzw. Webcrawlern angesteuert, die eure Domain besuchen. Die meisten automatisierten Crawler respektieren die enthaltenen Vorgaben. Grundsätzlich gibt es aber keine Garantie, dass andere Crawler sich an eure Vorgaben halten. Hierbei handelt es sich also eher um Richtlinien.
Außerdem können vom Crawling ausgeschlossene URLs trotzdem gefunden und somit indexiert werden. Dies passiert zum Beispiel, wenn andere Domains auf die ausgeschlossenen Seiten verlinken. Wenn ihr URLs vom Index ausschließen wollt, dann verwendet hierzu lieber das noindex-Meta-Tag und nicht die robots.txt.
Da die robots.txt früh von Crawlern aufgerufen wird, sollte hier auch die Sitemap.xml hinterlegt sein, um Crawlern diese schnellstmöglich zur Verfügung zu stellen.
Braucht man zwingend eine robots.txt?
Nicht immer halten Website-Inhaber die Implementierung einer Robots.txt für sinnvoll oder notwendig. Dabei kann es passieren, dass der Webhost bei fehlender Robots.txt eine 404-Fehlermeldung ausspielt, was zu seltsamen Verhalten führen kann. Das Risiko liegt hierbei aber unter 1%. Geht daher lieber auf Nummer sicher und legt eine leere robots.txt an als gar keine.
Welche Vorteile bietet die robots.txt für Domainbetreiber?
Die robots.txt bietet vielseitige Möglichkeiten, um das Crawling eurer Domain zu steuern. Wenn ihr also den Eindruck habt, dass eure Server zu viele Anfragen von Crawlern bekommen und diese somit überlasten, solltet ihr unrelevante Verzeichnisse, Dateien oder Seiten vom Crawling ausschließen. Dies entlastet euren Server und managet das begrenzte Crawlbudget.
Neben dieser Schutzvorkehrung habt ihr aber auch die Möglichkeit Medien- und Ressourcendateien vor Google zu verbergen und somit das Anzeigen in den Google-Suchergebnissen zu verhindern. Bedenkt jedoch bei den Medien-Dateien, dass Nutzer diese weiterhin aufrufen und auch verlinken können.
Das Ausschließen von Ressourcen-Dateien kann zudem von Nachteil für euch sein, wenn diese Ressourcen essenziell für das Verständnis des Contents sind. Bedenkt dabei, dass Google Ressourcen, die ihr per robots.txt vom Crawling ausschließt, auch nicht auf den einzelnen Seiten lesen kann und den Inhalt daher gegebenenfalls schlechter versteht.
Bestimmte Verzeichnisse, die aus technischen Gründen existieren, aber für Suchmaschinen und Nutzern keinen Mehrwert bieten, können also in den meisten Fällen vom Crawling ausgeschlossen werden.
Gerade bei großen Domains mit sehr vielen Seiten kann hier Webseiten-weit das gesamte Crawlbudget gut gesteuert werden, da redundante Seiten und bestimmte Dokumente ausgeschlossen werden können und der Crawler nur relevante Seiten aufruft.
Die robots.txt bietet somit folgende Vorteile:
- Zielgerichtete Steuerung von Webcrawlern und somit Steuerung des Crawlbudgets
- Verstecken von Medien-Dateien in der Google-Suche
- Hilfestellung für Webcrawler durch Verlinkung der Sitemap
- Crawler können einzeln angesprochen und mit unterschiedlichen Verhaltensmustern ausgestattet werden
Wie ist eine korrekte Robots.txt aufgebaut?
Um nicht jede URL einzeln in der robots.txt aufführen zu müssen, könnt ihr mit regulären Ausdrücken arbeiten. Aber Vorsicht: Die robots.txt ist ein sehr sensibles Dokument. Bereits kleine Syntaxfehler können dazu führen, dass Vorgaben nicht befolgt werden. Durch das Fehlen eines „$“ kann z.B. ein ganzes Verzeichnis vom Crawling ausgeschlossen werden, anstatt nur Seiten mit einer bestimmten Endung. Das „$“ stellt dabei eine sogenannten Wildcard dar. Was das genau ist und welche für die robots.txt gebräuchlich sind, zeigen wir euch in den nächsten Abschnitten.
Auch bekannte Bot-Namen listen wir euch am Ende dieses Abschnittes auf.
Aufbau der Robots.txt
Der Aufbau der robots.txt folgt einer bestimmten Reihenfolge, beginnend mit der Formulierung „User-Agent“ und der Benennung des anvisierten Bots. Ein User-Agent ist dabei laut Definition ein Mittel zur Angabe eines bestimmten Crawlers oder einer Gruppe von Crawlern.
Das Kürzel „*“ steht dabei für eine generelle Aussage, die alle Bots betrifft. Sollen mehrere verschiedene (aber nicht alle) User Agents mit denselben Vorgaben angesprochen werden, erhält jeder Bot eine eigene Zeile.

Aufbau einer Robots.txt
Nach der Zielangabe kommen die hierauf bezogenen Vorgaben.
Im Prinzip gibt es nur zwei Typen von Anweisungen. „Allow“ und „Disallow“. Allow bedeutet dabei, dass dem Crawler erlaubt wird, folgende/s Seite/Verzeichnis/Datei zu crawlen, während Disallow genau das Gegenteil bewirkt.
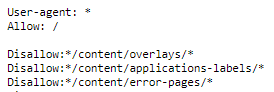
Allow & Disallow Vorgaben für Crawler in der Robots.txt
In dem Screenshot wird allen Crawlern (User-agent: *) erlaubt, sämtliche URLs der Seite zu crawlen (Allow: /). Gefolgt wird diese Direktive von Eingrenzungen. In diesem Beispiel wird somit allen Crawlern untersagt, Seiten aus den Verzeichnissen /content/overlays/, /content/applications-labels/ und /content/error-pages/ zu crawlen. Die „*“ vor und nach dem Verzeichnis dienen hierbei als Platzhalter für jegliche Zeichenketten, die auf diese Zeichen folgen. Dazu später mehr.
Beim Verwenden mehrerer Vorgaben zu einem spezifischen Crawler solltet ihr auch darauf achten, wie ihr die Angaben macht. Fangt am besten damit an, was ihr erlauben wollt (allow: ) und endet mit den Verzeichnissen, die nicht gecrawlt werden sollen (disallow: ). Allgemein gesprochen hat nämlich der Eintrag Vorrang, der, gemessen an der URL-Länge, spezifischer ist. In den meisten Fällen ist das die disallow Anweisung, so dass die vorangegangene Allow-Anweisung überschrieben wird. Solltet ihr widersprüchliche Regeln angeben, wird die am wenigsten restriktive Angabe verwendet.
Beispiele:
| Beispiel-URL | Beispiel robots.txt |
| https://www.luna-park.de/seo | User-agent: *
Allow: /seo Disallow: /
Urteil: URL darf gecrawlt werden, da Sie die spezifischere Angabe ist. |
| https://www.luna-park.de/seo/contentoptimierung
|
User-agent: *
Allow: /seo/ Disallow: /seo/ Urteil: URL darf gecrawlt werden, da die Angaben widersprüchlich sind und somit die weniger restriktive greift. |
Die Platzierung der Sitemap ist hierbei nicht festgelegt. Diese kann am Kopf oder aber auch am Ende der Datei erfolgen. Wichtig hierbei ist nur, dass ihr die Vorgabe „Sitemap:“ vor der absoluten URL der Sitemap angebt – relative URLs funktionieren hier nicht.
Wichtig zu beachten ist noch, dass die robots.txt eine Datei-Größe von über 500 KiB (Kibibyte) nicht überschreiten darf, da sie sonst von Google ignoriert wird. Diese Grenze unterschreitet man aber in der Regel deutlich.
Eure Robots.txt könnt ihr problemlos hier auf Größe und Funktion testen: https://support.google.com/webmasters/answer/6062598?hl=de
Standardmäßig crawlt Google übrigens alle Unterseiten. Ihr müsst dazu keine Allow-Anweisung für alle Seiten aufführen.
Reguläre Ausdrücke: Nutzbare Wildcards für die robots.txt
Durch die Verwendung von regulären Ausdrücken könnt ihr eure Vorgaben vereinfachen. Die Suchmaschinen von Google, Bing und Yahoo erlauben dabei die Verwendung von zwei Wildcards. Diese sind zum einen der Asterisk (*) und das Dollarzeichen ($)
- Der Asterisk (*) dient hier als Platzhalter für jegliche Zeichenketten.
So wird mit der Direktive „Disallow: /*suche*/“ verboten, dass sämtliche Webseiten, die die Zeichenabfolge „suche“ beinhalten, gecrawlt werden.
Dies wird oft verwendet, um Seiten mit Parametern auszuschließen. (Disallow: /*?)
- Beim Dollarzeichen ($) handelt es sich um einen Platzhalter, der das Ende einer Zeichenkette symbolisiert.
So werden mit der Direktive „Disallow= *.suche$“ alle Seiten vom Crawling ausgeschlossen, die auf .suche enden. Dies kann man insbesondere dafür nutzen, um bestimmte Formate wie z.B. PDF-Dateien vom Crawling auszuschließen (Disallow= /*.pdf$)
Hier sind noch ein paar weitere Beispiele aufgelistet:
User-agent: *
Disallow: /java*/ à alle Unterverzeichnisse, die mit „java“ beginnen
Disallow: /*intern*/ à alle Unterverzeichnisse, die „intern“ enthalten
Disallow: /*.jpg$ à alle Dateien, die auf „.jpg“ enden
Bekannte Webcrawler und ihre Namen
Im Internet gibt es eine Vielzahl an Bots und Webcrawlern. Im Folgenden möchten wir euch die gebräuchlichsten Bots von Suchmaschinen aufzeigen.
| Crawler | Name |
| Googlebot für die Websuche (mobile sowie Desktop) | Googlebot |
| Googlebot für Nachrichten | Googlebot-News |
| Googlebot für Bilder | Googlebot-Image |
| Googlebot für Videos | Googlebot-Video |
| Google AdsBot | AdsBot-Google |
| Yahoobot | Slurp |
| Bingbot für die Websuche | bingbot |
Eine Auflistung aller Google-Bots findet ihr hier: https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers?hl=de
Die gebräuchlichsten Anwendungen in der Robots.txt
Aufgrund der hohen Sensibilität dieses Dokuments haben wir euch einige Direktiven und deren Formulierungen aufgelistet, die ihr für eure Robots.txt leicht anpassen könnt.
| Verwendungszweck | Direktive |
| Eine bestimmte Seite für alle Crawler ausschließen | User-agent: *
Disallow: /unterseite.html |
| Eine bestimmte Seite für einen bestimmten Crawler ausschließen | User-agent: Name des Bots
Disallow: /unterseite.html |
| Ein bestimmtes Verzeichnis mit allen Unterseiten für alle Crawler ausschließen | User-agent: *
Disallow: /verzeichnis/ |
| Alle PDF-Dateien für alle Crawler ausschließen | User-agent: *
Disallow: *.pdf$ |
Für unterschiedliche Crawler, unterschiedliche Verzeichnisse ausschließen
|
User-Agent: *
Disallow: /wp-admin/
User-Agent: Googlebot Disallow:
User-Agent: Googlebot-Image Disallow: /verzeichnisxyz/ Disallow: /tmp/
|
| Alle Crawler dürfen alles crawlen + Hinterlegen der Sitemap | User-Agent: *
Disallow:
Sitemap: http://www.domain.de/sitemap.xml |
Wie reiche ich eine neue robots.txt bei Google ein?
Solltet ihr nun eure Robots.txt neu erstellt, getestet und angelegt haben, solltet ihr eure Arbeit auch Google bekannt machen. Normalerweise findet Google diese schnell, da der Verankerungspfad ja vordefiniert ist. Wir hatten jedoch auch schon den Fall, dass Google diese nicht gefunden hat bzw. die alte Version der robots.txt gecacht hatte, weswegen wir hier etwas nachgeholfen haben. Dafür benötigt ihr einen Zugang zur Google Search Console. Unter diesem Link könnt ihr dann eure robots.txt bearbeiten und die Änderungen an Google schicken.
https://www.google.com/webmasters/tools/robots-testing-tool
Leider ist diese Funktion aktuell nicht in der Standard-Ansicht von der Google Search Console verlinkt.
Screenshot Robots.txt_GSC einrichten
Worauf muss man bei der robots.txt achten?
Durch das Ausschließen eines Verzeichnisses (gewollt oder ungewollt), können sich auch die Rankings verschlechtern. Denn die ausgeschlossenen Seiten können gegebenenfalls nicht als Zielseite für die Suchergebnisse verwendet werden, da Google sie vom Crawling ausschließt. Andererseits können aber auch Seiten, die ihr vom Crawling ausgeschlossen habt, als Suchergebnis-Seiten ausgespielt werden, wenn diese von anderen Domains stark verlinkt werden. Wenn Seiten definitiv nicht indexiert werden sollen, ist die robots.txt also nicht die richtige Methode. Verwendet stattdessen die Meta-Robots auf den jeweiligen Seiten und setzt diese auf „noindex“.
Ein typischer Fehler hierbei ist, dass Seiten, die aus dem Index ausgeschlossen werden sollen, aktuell aber noch indexiert sind, gleichzeitig per Meta-Robotos-Tag auf noindex gestellt und in der robots.txt vom Crawling ausgeschlossen werden. So verhindert ihr zwar, dass sie weiterhin gecrawlt werden, aus dem Index verschwinden sie aber nicht, da Google die Meta-Robots-Anweisung nicht mehr liest. Seid euch also bewusst, dass Änderungen an eurer Seite, egal in welcher Form, auch immer von Google gecrawlt werden müssen, um sie zu berücksichtigen.
Fazit
Die korrekte Verwendung der robots.txt hat keine direkte Auswirkung auf das Ranking in den SERPs. In erster Linie kann mit dieser Textdatei der Googlebot gesteuert werden, damit das Crawlbudget ideal genutzt wird und relevante URLs gecrawlt werden. Eine fehlerhafte Verwendung kann jedoch zu massiven Abwertungen führen, da Google Seiten und somit euren hochwertigen Content nicht lesen und daher auch nicht indexieren kann.




